

Snowflake ETL Process Step by Step | Easy Walkthrough
What is Snowflake ETL
Snowflake ETL is the process of transferring data from multiple sources into the Snowflake platform, so that it can be utilized for analysis.
The term ETL refers to Extract, Transform, Load and describes three key steps involved in the preparation of data for analytics or reporting.
- Extract Data from different systems like databases, applications files, or cloud services.
- Transform – Clean and convert the data in order that it is in line with the structure that is required. This might be done by fixing formats, removing duplicates, combining data sets or implementing business rules.
- Upload – Transfer the data that has been processed into Snowflake which makes it accessible for dashboards, queries or other advanced applications.
One of the advantages of Snowflake is that it works with it both conventional ETL as well as ELT (Extract or Load data, then Transform).
In the typical ETL flow it transforms the information prior being loaded. With Snowflake it is possible to load raw data first, and then perform transformations inside the warehouse with SQL, Snowflake Tasks & Streams, or other external ETL software.
This strategy gives organizations the flexibility they need. Examples:
- Data on sales can be retrieved directly from the ERP system, then transformed to conform to reporting standards, and later loaded into Snowflake to be analyzed.
- The raw data could be loaded directly into Snowflake and later transformed to reduce the time required for data to be ready to use.
Snowflake can also be used with the most popular ETL tools, such as Fivetran, Matillion, Informatica Talend, Fivetran, and dbt and makes it simpler for teams to create pipelines that do not require a lot of infrastructure management.
By handling huge amounts of semi-structured and structured information effectively, Snowflake helps businesses move more quickly from raw data into important insights.
Why Use Snowflake for ETL?
Snowflake ETL is extensively used since it enables teams to organize and process data more quickly without the burden of infrastructure management.
Traditional ETL pipelines tend to slow down when data is growing or costs increase as the number of servers added.
With Snowflake the ETL process is made simpler because storage and computation are separate and resources can increase or decrease based on the load.
Performance Benefits
Snowflake ETL delivers strong performance due to its multi-cluster structure. Queries can run simultaneously without interfering which eliminates bottlenecks.
For instance when one team is extracting data and another team is processing it, both processes will be completed without a wait for each other to finish.
In many instances, Snowflake automatically optimizes queries which means that transformations are completed faster than traditional ETL systems.
This means that there is less time waiting in the form of reports, analytics and other.
Scalability & Cost Optimization
In addition, the ability to expand ETL pipelines is another significant benefit. With Snowflake it is not necessary to purchase extra hardware in order to handle massive data volumes.
Instead, you can compute to handle large tasks and reduce it once the task is complete. This lets you pay for unneeded resources that are a typical problem in traditional ETL configurations.
Storage also comes with a lower cost due to the fact that Snowflake compresses data on a regular basis and you pay only for the data you keep.
For companies that have multiple ETL pipelines The combination of the ability to scale as well as pay-per-use prices lets you handle data growth without spiralling costs.
Many teams appreciate this when they are transferring from previous ETL platforms that needed regular upgrade of the hardware
Snowflake ETL vs Traditional ETL
Feature / Factor | Snowflake ETL | Traditional ETL |
Performance | Multi-cluster processing allows parallel queries without slowdowns. | Limited by server capacity, often faces bottlenecks. |
Scalability | Compute and storage scale independently as needed. | Requires adding more servers or hardware upgrades. |
Cost Optimization | Pay only for used compute and storage; auto-compression saves space. | Higher fixed costs due to hardware and licenses. |
Setup & Maintenance | Cloud-native, no infrastructure management. | Requires setup, upgrades, and ongoing maintenance. |
Flexibility | Handles structured and semi-structured data (JSON, Avro, Parquet). | Mostly optimized for structured data only. |
Time to Insights | Faster transformations with built-in query optimization. | Slower due to manual optimization and hardware limits. |
Want to learn Snowflake? If yes Click here
or want to continue reading about Snowflake ETL Process Step-by-Step Process
Step by Step Snowflake ETL Process
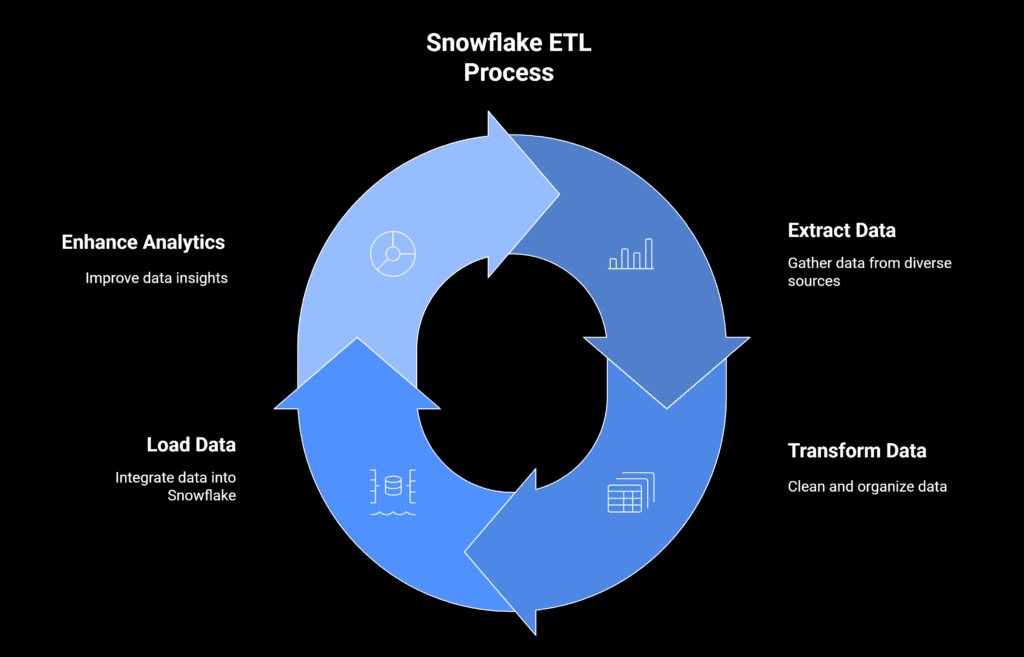
Snowflake ETL is a quick and easy way to move raw data onto the Snowflake cloud platform, then clean it, and then prepare it for analysis.
ETL refers to Extract, Transform and Load and each step makes sure that the data is prepared for machine learning or reporting.
Many students struggle because they aren’t sure how to set up the correct process in Snowflake. Below is a clear step-by-step guideline.
Step 1 - Extract Data into Snowflake
Extraction refers to the extraction of information from multiple sources, including database databases (MySQL, SQL Server, Oracle) or cloud storage (AWS S3, Azure Blob, Google Cloud Storage) as well as SaaS platforms (Salesforce, Shopify, HubSpot).
- In Snowflake the process is usually accomplished using staging of the data in advance. For instance, the files are stored on an external or internal stage prior to loading.
- Tools such as Snowpipe, Fivetran, Informatica or Matillion can be automated to automate continuous extraction to Snowflake.
- The most important issue is speed and precision. Snowflake can solve this problem by offering simultaneous data intake and processing huge file sizes with no breakage.
Step 2 - Transform Data in Snowflake
When data is stored inside Snowflake typically, it needs to be cleansed or modified. The process of transformation can include:
- Remove duplicates, fix null values or implement business rules.
- The conversion of formats (e.g., JSON – table-based tables).
- The joining of multiple data sources allows for unification in the report.
Snowflake is efficient in this case because transformations can be performed within Snowflake with SQL or external ETL tools which push jobs directly to the platform. - The main benefit is ELT’s style (Extract Load – Transform) which means that raw data is first loaded and then transformed using Snowflake’s computation engine. This can reduce time and effort in comparison to older ETL systems.
Step 3 - Load Data for Analytics
The last stage is loading the transformed data into tables that can be utilized by BI tools, such as Tableau Power BI, Tableau, Looker.
- Snowflake can be used to create reports or materialized views. tables which optimize data for queries.
- Information is stored using a columnar format therefore analytical queries are able to run quicker.
It is a good idea to utilize snowflake’s virtual warehouses to isolate ETL work from reporting tasks so that they can both run without performance problems.
Define Snowflake ETL Pipeline
A Snowflake data pipeline provides a structured workflow for businesses to transform raw data into a usable and clean format and then store it in the Snowflake data platform.
This pipeline’s purpose is to collect data from external services, databases or applications in one location and prepare it for analytics.
Snowflake’s cloud native design is what makes it different from other ETL methods. Snowflake’s features such as automatic scalability, semi-structured handling of data, and near-real-time loading, allow users to avoid heavy on-premises servers and complex staging systems.
The ETL process is now faster, more cost-effective, and easier for users to maintain.
Snowflake ETL Pipeline Components
- Extracting Data
- Data is collected in multiple sources, such as ERP/CRM systems, operational databases, APIs or log files.
- Snowflake offers native connectors that work with third-party tools such as Fivetran, Talend or Informatica, to ensure seamless extraction.
- It supports many formats, including CSV and JSON.
- Transforming Data
- Snowflake often requires cleansing, enrichment or standardization of raw data once it reaches the system.
- Snowflake can perform transformations using SQL-based SQL0_ operations (in-database transforms), reducing data movement.
- Data consistency and analysis are ensured by applying business rules, aggregates, and quality checks.
- Loading Data
- The last step is to store the data in Snowflake tables.
- Snowflake supports batch load (large data chunks at intervals), and continual loading by using Snowpipe. This allows data to be streamed as soon as they are available.
- The flexibility of this system allows organisations to choose between scheduled updates or near-real-time reporting.
Why Snowflake ETL pipelines are valuable
- Scalability with no limits– Virtual warehouses can be scaled down or up depending on the workload.
- Lower operating overhead– No need for servers or complex infrastructure.
- Unified Data Handling– Handles structured and semistructured data natively.
- Faster insights– Data is available much faster for dashboards and AI/ML models.
- Automation – With Snowpipe, task scheduling and other tools, the majority of manual interventions can be eliminated.
The Best Practices for Building an ETL Snowflake Pipeline
- Use Snowpipe to load data in real-time, or close to real-time.
- Use SQL, stored procedures or external ETL tools to organize transformations.
- Monitor and optimize performance with query histories and resource monitors.
- Use data governance, role-based access control and pipeline security.
- To keep queries as efficient as possible, it is important to partition and cluster large tables.
Want to learn Snowflake? If yes Click here
or want to continue reading about Snowflake ETL Process Step-by-Step Process
Top ETL Tools for Snowflake
The top ETL software for Snowflake is essential for any company that wishes to transfer data from various sources to Snowflake faster as well as with little effort.
Although Snowflake is a cloud-based data warehouse that is powerful, it is not able to perform ETL by itself.
It requires an additional ETL software or tool to pull data from your systems, convert it into formats that are usable, and then load in Snowflake.
Selecting the right tool will make it easier to save time, lower expenses, and increase the overall quality of data.
1. Matillion
- It is compatible with Snowflake designed by cloud platform providers, Matillion operates in the cloud and is able to connect directly to Snowflake.
- Key Benefits:
- Visual interface with no code for building ETL pipelines.
- Native push-down ELT to improve performance.
- Easy to set up Easy to set up, no dependence on engineering groups.
Ideal for: mid-sized businesses or data teams who want rapid results, without the burden of code.
2. Fivetran
- The reason it is a good fit with Snowflake: Fivetran focuses on automated ELT and offloads the task of transformation to the powerful computing engine of Snowflake.
- Key Benefits:
- Pre-built connectors designed for SaaS applications, databases APIs, and databases.
- Handles schema shifts and changes in a way that is automatic.
- There is virtually no maintenance once pipelines are in place.
Ideal for: Businesses that require constant, reliable data syncs with little effort.
3. Talend
- Its compatibility: Why it works well Snowflake: Talend provides both enterprise and open-source editions. It’s more than only an ETL tool, but also a complete platform for managing data.
- Key Benefits:
- Advanced tools for data quality, profiling, and tools for governance.
- Supports real-time and batch processing.
- Solid compliance support (GDPR, HIPAA).
Ideal for: Companies which require control, oversight and flexibility across a variety of data systems.
4. Informatica
- The reason it is compatible when it is used with Snowflake: Informatica is one of the top names in ETL and is now offering a strong cloud native integration to Snowflake.
Key Benefits:- Secure and enterprise-grade scalability.
- The deep cataloging of metadata, metadata as well as lineage capability.
- Can handle petabyte-scale workloads.
Best for: Larger organizations that require strict compliance, large volume of data, and complicated integration requirements.
5. Apache Airflow (with Snowflake Operator)
- It is a good fit Why it works well Snowflake: Airflow is an open-source orchestration software that allows developers the freedom to create workflows. Through Snowflake Operator, it is a direct integration. Snowflake Operator, it integrates directly.
- Key Benefits:
Highly flexible pipelines that can be made highly customizable.
Monitoring and scheduling is a must for data workflows. It is free to use and has an active community of open-source developers.
Ideal for: Teams with a heavy engineering component who require flexibility and total control, not pre-built connectors.
Considerations When Choosing an ETL Tool for Snowflake
The right tool to choose isn’t about “best overall” but about the right solution for your specific needs. These are the main aspects to consider:
1. Budget and Pricing Model
- ETL tools can be priced per user, per connector or based on the volume of data.
- For instance, Fivetran charges by the amount of active rows that are processed, which can be costly in large quantities, whereas Matillion utilizes an instance-based pricing system.
- How to estimate the monthly volume of data movement and then compare the costs between different tools.
2. Data Sources and Connectors
- What is important: If your company is using a lot of SaaS applications (Salesforce, HubSpot, Shopify) an application with built-in connectors such as Fivetran is the best choice.
- If your data is from a custom system, Airflow or Talend may be better suited.
What you need to do: Create an inventory of all your data sources, and then make sure that the ETL tool can handle these sources.
3. User-Friendliness in comparison to Flexibility
- Tools that do not require code such as Matillion are easy for businesses, but they aren’t as customizable.
- In contrast, Airflow offers unlimited flexibility however, it requires developers expertise.
- What you can do is balance your team’s abilities and the tools’ level of complexity.
- Teams that are not technical will be able to benefit from Matillion or Fivetran and engineering teams might be more comfortable with Airflow.
4. Scalability and Performance
- What is important When your data is growing it is essential to have pipelines that are scalable without causing slowdown or getting too expensive.
- Snowflake’s compute model can support push-down ELT and tools such as Matillion and Fivetran can better handle the increase.
What to do: Determine whether the tool can handle the parallel load, Auto-scaling, or incremental updates.
5. Data Governance and Compliance
- What is the significance? In industries such as finance or healthcare, tools for compliance (GDPR, HIPAA, SOC 2) are required. Tools such as Talend and Informatica excel in this area with lineage and data governance and cataloging.
- How to proceed: Assess the requirements for compliance before selecting an instrument to prevent the risk of future problems.
6. Maintenance and Support
- The reason it is important Tools differ in the amount of they require ongoing maintenance.
- Fivetran is practically maintenance-free; however, Airflow requires regular maintenance by engineers.
What to do: Take into account the hidden costs of maintenance, as well as the accessibility of community or vendor assistance.
Key Takeaway
There isn’t one “best” ETL tool for Snowflake. The best choice is contingent on the budget you have, the data sources, the expertise of your team, and your compliance requirements.
- If you are looking for the simplicity and speed of automation, then go for Fivetran.
- If you’re looking for no-code pipeline construction, choose Matillion.
- To manage your enterprise, pick Informatica or Talend.
- If your company is seeking flexibility and control that is open source choose Apache Airflow.
The best choice is to balance features, cost and long-term scalability to ensure that your Snowflake environment is flexible and future-proof.
Why Do We Need ETL for Snowflake?
Snowflake ETL is necessary since raw data derived from a variety of sources isn’t always available for analysis.
Companies collect data from databases, applications APIs, files, and other sources however, this data can be unorganized, inconsistent or stored in various formats.
Without ETL loading these files directly to Snowflake makes it difficult to search, slows performance, and adds the cost of storage.
ETL (Extract Transform, Load) resolves this issue by preparing data prior to it being loaded into Snowflake.
- Extract Extract data from a variety of systems (ERP CRM IoT, cloud apps and more. ).
- Transform Clean, filter and standardize the data so that it is compatible with Snowflake’s design.
- Load to push the prepared data into Snowflake tables for dashboards, analytics and machine learning.
Key Reasons We Need ETL in Snowflake
1. Data Quality and Consistency
Snowflake is best suited to well-organized, clean data. ETL ensures that duplicates are eliminated and missing values are corrected and formats are consistent. This means that your dashboards and reports will show accurate results.
2. Performance Optimization
The process of transforming data prior to loading decreases the volume of processing that occurs within Snowflake. This decreases CPU usage and speeds up queries as well as reducing costs.
3. Integration from Multiple Sources
The majority of organizations do not rely on one data management system. ETL lets the data of ERP, Salesforce, Google Analytics, IoT sensors, or even old databases to be merged into Snowflake to provide a complete view.
4. Scalability and Automation
ETL pipelines can automate repetitive tasks, such as daily refreshes of data and batch loading. This enables teams to expand operations on data without manual effort while keeping Snowflake data up-to-date.
5. Compliance and Security
Prior to loading the sensitive information into Snowflake, ETL can mask personal information, encrypt fields, or eliminate data that is not required for analysis. This is crucial for businesses complying with the GDPR and HIPAA and financial regulations for compliance.
Want to learn Snowflake? If yes Click here
or want to continue reading about Snowflake ETL Process Step-by-Step Process
Best Practices for Snowflake ETL
The Snowflake ETL platform is extensively used as it makes data moving as well as storage, transformation and.
However, many teams experience delays in performance and increasing costs if they do not follow the correct procedures.
The secret to success in using Snowflake ETL is applying methods for tuning performance as well as methods to optimize costs when developing data pipelines.
Here are some practical strategies to address common problems for both novice and experienced users.
Performance Tuning in Snowflake ETL
1. Choose the Right Warehouse Size
- Start small, and then increase the size only when necessary.
- Utilizing a warehouse that is too big for each ETL task is wasteful of resources.
- Make use of Multi-cluster warehouses only for large-scale concurrency loads and not for routine tasks.
2. Leverage Query Caching
- Snowflake automatically stores query results. Use cached data instead of running costly queries.
- Create ETL workflows to reduce unnecessary queries.
3. Use Clustering and Micro-Partitioning
- Snowflake automatically divides data. However, you are able to create clustering keys for columns that are frequently filtered.
- This decreases the time to scan and speeds up the processing of large ETL jobs.
4. Avoid SELECT *** in ETL Queries
- Make sure you select only the columns that are required.
- Wide queries increase the amount of I/O available and can slow down the process of transformation.
5. Parallelize ETL Loads
- Break up large ETL tasks into smaller batches, and perform the tasks in parallel.
- The Snowflake command COPY allows multiple files to be loaded which speed the bulk loading process.
Cost Optimization in Snowflake ETL
1. Use Auto-Suspend and Auto-Resume
- Create warehouses that automatically suspend in idle.
- This means that there is no need to bill for unused computes and reduces the cost significantly.
2. Optimize Storage using Retention Settings for Data
- Snowflake stores older data within Time Travel. Change the retention time to meet your compliance requirements instead of leaving it as the default.
- Shorter retention = lower storage costs.
3. Track ETL Job Status using Historical Query
- Utilize the View of Query History and Snowsight dashboards to spot costly or long-running ETL queries.
- Optimize or modify queries that use high computing credits.
4. Use Streams and Tasks for Incremental Loads
- Instead of reloading tables with full data instead, you can use the incremental method of ETL using Tasks and Streams.
- This decreases compute as well as storage use.
5. Leverage Resource Monitors
- Set spending limits through Resource Monitors to prevent unexpected credit overages.
- Alerts assist teams in deciding how to act before costs spiral out of hand.
Common Challenges in Snowflake ETL (and Fixes)
Snowflake ETL faces real challenges around error handling and data quality issues. If not solved, these can break pipelines, delay reports, and increase costs. Below are the practical fixes with SQL examples to help you handle them effectively.
1. Error Handling in Snowflake ETL
Common Mistakes :
- Schema mismatch between source and target.
- Invalid formats (e.g., wrong date or numeric values).
- Permission errors due to missing roles.
- SQL query failures during transformation.
Fixes with Examples:
a) Use TRY_CAST for Safe Conversions
Instead of failing when a value can’t be converted, TRY_CAST returns NULL
SELECT
TRY_CAST(column1 AS DATE) AS safe_date
FROM raw_data;
This prevents pipeline crashes if invalid date values appear.
b) Error Logging Table
Capture failed rows with error messages for debugging.
CREATE TABLE etl_error_log (
id STRING,
error_message STRING,
error_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
c) Retry Logic with Snowflake Tasks
For transient failures, schedule retries:
CREATE TASK etl_task
WAREHOUSE = my_wh
SCHEDULE = '5 MINUTE'
AS
CALL run_etl_procedure();
If the task fails, Snowflake automatically retries in the next schedule.
2. Data Quality Issues in Snowflake ETL
Common Mistakes :
- Duplicate rows.
- Null values in important fields.
- Inconsistent date and string formats.
- Outdated or stale data.
Fixes with Examples:
a) Remove Duplicates with ROW_NUMBER()
Keep only the latest record:
SELECT *
FROM (
SELECT *,
ROW_NUMBER() OVER (PARTITION BY customer_id ORDER BY updated_at DESC) AS r n
FROM staging_customers
) t
WHERE rn = 1;
b) Handle Missing Values with Defaults
Replace NULL values with a default:
SELECT
COALESCE(order_status, 'Pending') AS clean_status
FROM staging_orders;
c)Standardize Formats During Transformation
Keep dates and strings consistent:
SELECT
TO_DATE(order_date, 'YYYY-MM-DD') AS formatted_date,
TRIM(customer_name) AS clean_name
FROM raw_orders;
d)Monitor Data with BI Dashboards
- Connect Snowflake to Tableau / Power BI / Looker.
- Track null counts, row counts, load times.
- Set alerts when anomalies appear.
Want to learn Snowflake? If yes Click here
or want to continue reading about Snowflake ETL Process Step-by-Step Process
State the difference between ETL vs ELT in Snowflake

ETL vs ELT is one of the most common topics when learning Snowflake. Both terms describe how data moves from different sources into a system like Snowflake, but they differ in the order of operations and how transformations are applied.
What is ETL?
ETL stands for Extract, Transform, Load.
- Extract – Data is pulled from the source system (databases, applications, APIs, etc.).
- Transform – Data is cleaned, formatted, and structured before entering the warehouse.
- Load – Once ready, the transformed data is loaded into Snowflake or another data warehouse.
👉 ETL is useful when transformations are heavy or must happen before data lands in the warehouse. For example, banking or healthcare systems often use ETL to apply strict data quality rules before storage.
What is ELT?
ELT stands for Extract, Load, Transform.
- Extract – Data is taken from the source.
- Load – Raw data is directly loaded into Snowflake.
- Transform – Data transformations happen inside Snowflake using SQL or built-in compute power.
👉 ELT is better suited for modern cloud warehouses like Snowflake. Since Snowflake is designed to scale, transformations are faster and cheaper when done after the load step.
Key Difference Between ETL and ELT
Factor | ETL | ELT |
Process Order | Extract → Transform → Load | Extract → Load → Transform |
Where Transformation Happens | Before data enters Snowflake | Inside Snowflake after loading |
Performance | Limited by external ETL tool or server | Uses Snowflake’s compute power (highly scalable) |
Use Case | Legacy systems, strict compliance data | Cloud-native systems, big data analytics |
Flexibility | Data must be structured before loading | Raw data can be stored, transformed anytime |
Why Snowflake Prefers ELT
Snowflake’s architecture is built to handle large-scale transformations directly in the warehouse. Instead of stressing external ETL tools, ELT allows you to:
- Store raw data first (no loss of details).
- Run on-demand transformations with SQL.
- Scale compute separately for transformation workloads.
- Pay only for the compute used during transformation.
That’s why most modern Snowflake projects rely on ELT as the default approach, while ETL is still used in cases where compliance or upstream formatting is required.
Which One Should You Use?
- Choose ETL when: you need strict pre-processing, have sensitive data, or use older systems.
- Choose ELT when: you want to take advantage of Snowflake’s scalability, flexibility, and cost efficiency.
In practice, many teams use a hybrid model where small pre-transformations happen outside (ETL) and the heavy lifting is done inside Snowflake (ELT).
Conclusion
Snowflake ETL is more than an approach to move data. It brings the benefits of cloud scalability and an easy method of the extraction, transformation, and loading of data onto an integrated platform.
As of now, you’ve realized how each step extraction, transformation and load works together to form a solid pipeline that supports decision-making and analytics.
The most important takeaways are easy:
- Start with small samples of datasets to get a better understanding of the process.
- Make use of Snowflake’s built-in features such as Snowpipe as well as Streams to automate tasks related to ETL.
- Make sure you are tuning your performance by maximizing queries and storage in order to cut the cost.
- Always validate data quality before loading it into production tables.
If you’re exploring Snowflake for the very first time, acquiring ETL in a structured manner can save you many hours of trial and error.
The process described here will give you a solid base but the actual depth is gained through hands-on experience.
If you’re keen to master Snowflake ETL pipelines by integrating them into real-world scenarios enrolling in the Snowflake Course which covers advanced scenarios automation, integration with the latest ETL tools.
FAQ's
There isn’t a single “best” tool, but some popular ETL tools for Snowflake are Fivetran, Talend, Informatica, Matillion, and dbt (for ELT). The right tool depends on your need:
- Simple, no-code pipelines → Fivetran, Stitch
- Enterprise-grade ETL → Informatica, Talend
- Transformations inside Snowflake (ELT) → dbt, Matillion
No, Snowflake does not have a dedicated ETL tool. Instead, Snowflake is a cloud data warehouse. You can use third-party ETL or ELT tools to move and transform data. Snowflake’s role is to store, process, and analyze data once it’s loaded.
DBT is not a traditional ETL tool. It is an ELT tool. With dbt, the Extract and Load steps are handled by another tool, and dbt focuses on the Transform step inside Snowflake using SQL.
Snowflake itself is not an ETL tool. However, it can be used as the target system for data migration. ETL tools connect with Snowflake to migrate data from on-premises or cloud databases into Snowflake.
When we say “Snowflake ETL,” it usually involves:
- Extract → Pulling data from source systems.
- Transform → Cleaning, filtering, and shaping the data.
- Load → Storing the transformed data into Snowflake tables.
Steps to integrate data into Snowflake:
- Choose an ETL tool (e.g., Fivetran, Talend, Informatica).
- Connect the source system (databases, APIs, files).
- Define transformation logic (clean, map, aggregate).
- Load the transformed data into Snowflake tables.
ETL tools work in three steps:
- Extract: Collect data from sources (databases, files, APIs).
- Transform: Clean, filter, join, and format the data.
- Load: Push the transformed data into the target system (like Snowflake).
Yes Modern pipelines are moving from ETL → ELT because:
- Cloud data warehouses (like Snowflake) are powerful enough to handle transformations internally.
- ELT is faster, more scalable, and cost-efficient.
ELT is preferred when:
- You use cloud data warehouses (Snowflake, BigQuery, Redshift).
- You want to load raw data quickly and transform it later.
- You need scalability and flexibility for large data.
In SQL Server, ETL is done through SSIS (SQL Server Integration Services). It extracts data from different sources, transforms it with SQL logic, and loads it into SQL Server or other targets.
You can insert data into Snowflake in three ways:
- Manual Insert: Using INSERT INTO SQL commands.
- Bulk Load: Using Snowflake’s COPY INTO command with files (CSV, JSON, Parquet).
- ETL Tools: Using third-party tools to automate inserts/loads.
For Snowflake, ELT is better because Snowflake’s architecture allows transformations after data is loaded. ETL is still used in some cases, but ELT fits cloud data warehousing more naturally.
The 3 stages are:
- Extract → Get data from multiple sources.
- Transform → Clean and reshape the data.
- Load → Store the final data into a target system like Snowflake.