

Snowflake Data Pipelines: Best Practices for Faster, Smarter Analytics
What is Snowflake data pipeline?
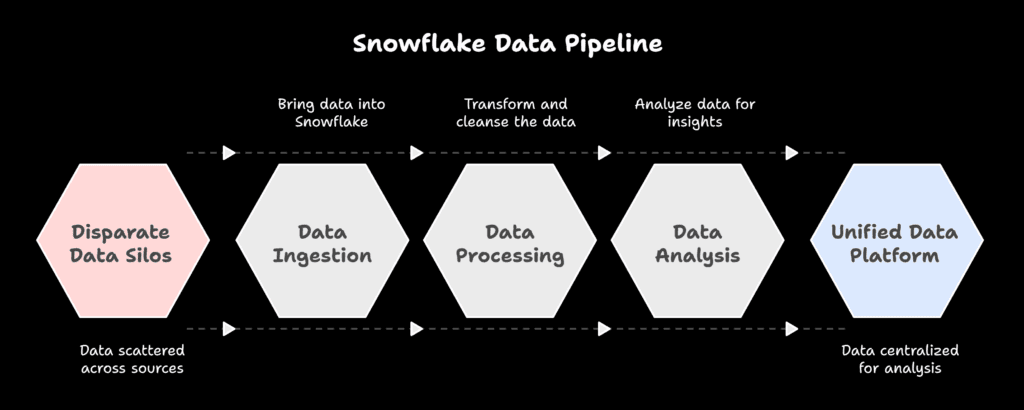
A Snowflake Data Pipeline is the process of moving, staging, and transforming data within the Snowflake cloud platform, from raw sources to analytics-ready datasets.
It involves ingestion tools, staging areas, transformation logic, and automation to ensure scalability, accuracy, and performance.
Core Components of a Snowflake Data Pipeline
A Snowflake data pipeline is not just a single tool or process, it’s a combination of connected layers that work together to move data from its source to its final destination.
Each layer plays a different role, but together they create a system that is fast, reliable, and scalable.
Below are the main components that form the backbone of a Snowflake pipeline:
1. Data Sources
Every pipeline starts with data sources, Where the original places where your data lives.
These can be:
- Operational Databases like MySQL, PostgreSQL, or Oracle.
- Application APIs such as Salesforce, HubSpot, or Google Analytics.
- Cloud Storage like Amazon S3, Azure Blob Storage, or Google Cloud Storage.
- Streaming Platforms such as Apache Kafka or AWS Kinesis for real-time feeds.
- Log Files and IoT Devices that generate high-frequency data.
Why this matters: Snowflake pipelines are source-agnostic, meaning they can pull from almost any system, whether the data arrives in batches once a day or streams every second.
2. Ingestion Layer (Getting Data Into Snowflake)
Once you know where the data is coming from, the next step is ingestion moving it into Snowflake.
There are multiple ways to do this:
- Snowpipe: Snowpipe Snowflake’s own continuous loading service that automatically ingests new files from cloud storage as soon as they arrive.
- Batch Loading: Using the COPY INTO command to load data in scheduled intervals.
- ETL/ELT Tools: Third-party platforms like Fivetran, Talend, or Informatica that can extract, load, and transform data.
Pro Tip: If your business needs real-time dashboards, Snowpipe + Streams can detect and load data almost instantly, keeping your analytics up-to-date.
3. Staging Area (The Temporary Holding Zone)
Before transformation, data usually passes through a staging area. This is a temporary storage zone that keeps raw data safe before processing. Snowflake supports two main types:
- Internal Stages : Storage managed entirely inside Snowflake (user, table, or named stages).
- External Stages : Pointers to external cloud storage like AWS S3, Azure Blob, or GCS.
Why it’s important:
- Allows you to separate raw and processed data.
- Gives flexibility to reload if transformations fail.
- Helps maintain data governance and auditing.
4. Transformation Layer (Shaping the Data)
Raw data is rarely ready for reporting. The transformation layer cleans, structures, and enriches it. This can include:
- Cleansing : Removing duplicates, fixing missing values.
- Standardization : Formatting dates, numbers, and text fields consistently.
- Enrichment : Combining multiple datasets to add more context.
In Snowflake, transformations can be handled using:
- Snowflake SQL scripts for direct data manipulation.
- DBT (Data Build Tool) for modular, version-controlled transformations.
- Stored Procedures & Tasks for automation and scheduling.
5. Orchestration & Automation (The Control Center)
A pipeline without automation is like a factory without a conveyor belt it works, but not efficiently.
Orchestration in Snowflake ensures processes happen in the right order, at the right time:
- Tasks : Automate and schedule transformations.
- Streams : Track changes in tables for Change Data Capture (CDC).
- Third-Party Orchestration Tools : Apache Airflow, Prefect, or Dagster for complex workflows.
6. Compute Layer (Processing Power)
In Snowflake, compute resources are provided by Virtual Warehouses independent clusters that can scale up or down depending on workload. This layer:
- Runs ingestion and transformation jobs.
- Allows parallel processing for faster results.
- Can be paused when not in use to save costs.
7. Output & Consumption Layer (The Final Destination)
The final step in the pipeline is delivering the processed data to its consumers:
- BI Tools like Tableau, Power BI, or Looker for analytics.
- Machine Learning Models for predictions and automation.
- APIs & Applications that feed processed data back into operational systems.
Why it matters: This is where data becomes actionable, driving business insights and decision-making.
Want to learn Snowflake? If yes Click here
or want to continue reading about Snowflake Data Pipeline best practices
Putting It All Together
A Snowflake data pipeline works like a well-organized delivery system:
- Data Sources provide the raw materials.
- Ingestion moves them into storage.
- Staging holds them temporarily.
- Transformation cleans and packages them.
- Orchestration ensures smooth operations.
- Compute power processes them efficiently.
- Output delivers them to the right audience.
When these components are designed well, you get a pipeline that is fast, flexible, and future-proof ready to handle growing data needs without breaking the bank.
State Different types of data pipeline
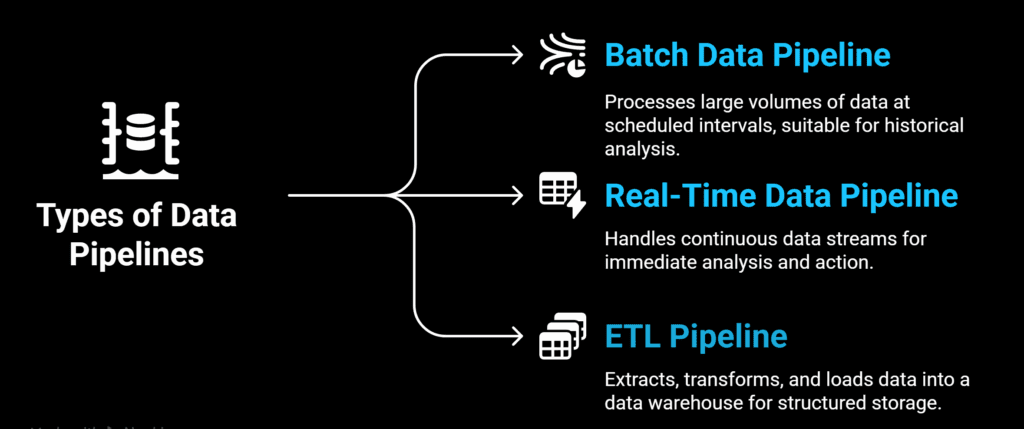
Data pipelines take several forms depending on how they transport and handle data.
These are the three most prevalent kinds:
a) Data pipelines for batches
Data is gathered over time and processed collectively in bulk through a batch pipeline.
Example: To update reports, a business collects sales transactions throughout the day and processes them at night.
Typical tools are Hadoop, Apache Spark, and Snowflake COPY INTO Command.
Ideal for: Big datasets that don’t need to be updated in real time.
b) Streaming Data Pipelines
- In a streaming pipeline, data is processed in real-time as soon as it is created.
- Example: A stock trading app needs instant updates when prices change.
- Common tools: Snowpipe in Snowflake, Kafka, AWS Kinesis.
Best for: IoT devices, banking systems, and fraud detection.
c) ETL and ELT Pipelines
- ETL (Extract, Transform, Load): Data is extracted, transformed into the right format, and then loaded into storage.
- ELT (Extract, Load, Transform): Data is extracted and loaded first, and transformation happens inside the data warehouse.
- Example: With Snowflake, ELT is very common because of its powerful SQL-based transformation.
Best for: Cloud data warehouses, analytics, and scalable systems.
Other Variations:
- Hybrid pipelines (mix of batch + streaming).
- Machine Learning pipelines (feeding raw data into ML models).
Benefits of Data Pipelines
Data pipelines offer numerous benefits for organizations and teams that rely on data for making strategic decisions.
a) Automation and Efficiency
Pipelines automate the lifting and shifting of data from one location to another. Less need for manual work and error correction processes.
For example, instead of having workers upload CSV files on a weekly basis, a pipeline continuously ingests data into Snowflake.
b) Scalability
Pipelines manage to process either small or enormously large volumes of data.
Systems hosted on the cloud scale automatically with data.
For example, an e-commerce platform can process millions of orders during peak sales periods without any lag.
c) Real-Time Insights
Beyond simple data lag, certain types of data movement permit instant decision making.
For example, banks stream data from their transaction systems to their monitoring systems.
d) Data Quality and Consistency
Data cleaning or transformation done in the pipeline guarantees cleansed, standardized, and trustworthy data.
For example, different date formats from various systems. These dates are standardized into a single format for analysis.
e) Cost Optimization
Cost associated with handling the data is lowered due to optimized storage, compute, and workflows.
For example, moving old data to low-cost storage while keeping recent data in quicker storage for fast analytics.
f) Better Collaboration Across Teams
With centralized and cleansed data, data scientists, analysts, and engineers work on the same dataset increasing accuracy and trust in the insights. Fosters cross-functional collaboration and enhances productivity.
Want to learn Snowflake? If yes Click here
or want to continue reading about Snowflake Data pipeline best practices
State Purpose of Data Pipelines
A pipeline’s primary objective is to make sure all information moves seamlessly to the required location for storage, cleansing, and analysis.
These are the core purposes that data pipelines serve:
1. Data Integration
In business, multiple systems are used, for instance, CRMs, ERPs, marketing tools, cloud applications, databases, and other ERPs.
A pipeline collects all this data into a single centralized repository, to a data warehouse such as Snowflake, BigQuery, and Redshift or to a data lake, for example, AWS S3 and Azure Data Lake.
This unification helps to minimize team silos and provides a single point of reference for accurate and reliable analysis.
2. Real Time Data Availability
Insights into data are crucial for modern companies and waiting for days to access them is not an option.
Data pipelines enable the processing of information in real or near real-time. Data feeds into dashboards, and fraud and customer applications immediately.
Example: In banking, a pipeline notifies the system of fraud and helps in processing suspicious transactions in seconds instead of hours.
3. Automation of Data Movement
Data movement used to involve intense manual work prior to pipelines. Engineers dealt with file transfers placing them in queues which were often riddled with mistakes.
With pipelines, the process is streamlined for extraction, loading, and transforming thus fully automating procedures with no human interference.
This boosts productivity while considerably lowering the chances of error.
4. Data Quality and Consistency
Duplicated, incomplete, and erroneous values are a standard in raw data.
Pipelines guarantee that uploaded data is reliable and ready for analysis after all the necessary steps, such as data cleaning, validation, and transformation, are completed.
This enables the decision makers to trust the information provided to them.
5. Scalability and Performance
A growing business will typically have an exponentially growing volume of data.
Pipelines enable large-scale data processing on cloud systems while maintaining order.
For instance, pipelines from Snowflake autonomously scale to handle terabytes and even petabytes of data.
6. Supporting Analytics and Machine Learning
Aside from moving data, pipelines prepare it for deeper analytical use.
Data that is structured and cleaned can be ingested by business intelligence dashboards and even by machine learning models.
This augments the ability of businesses to predict customer dynamics, streamline supply chain systems, and tailor product recommendations to individual users.
Best Practices for Performance & Cost Control
Best practices for performance and cost control in Snowflake include using the right virtual warehouse size, applying clustering keys for better query performance, leveraging auto-suspend and auto-resume, setting up resource monitors, pruning data with micro-partitioning, and managing storage efficiently with data retention policies.
a) Choose the Right Virtual Warehouse Size
A Snowflake Virtual Warehouse is the compute engine that runs your queries. Many teams overspend by using warehouses that are larger than necessary.
- Start small (like X-Small or Small) and scale up only when required.
- Use multi-cluster warehouses only for workloads with unpredictable spikes.
- Monitor query history in the Query Profile to understand performance before resizing.
b) Make use of Auto-Resume and Auto-Suspend
Auto-suspend is one of the most significant and cost-saving features in Snowflake. When warehouses are not in use, this automatically shuts them down and restarts them when necessary.
Establish brief suspension periods (e.g., 2–5 minutes).
Auto-resume should always be enabled so that tasks can continue without being assisted by humans.
Use this in testing and development settings where usage varies.
c) Apply Clustering Keys for Query Optimization
Snowflake automatically handles micro-partitioning, but for large datasets, queries may slow down if partitions are not aligned with common filters.
Define clustering keys on columns frequently used in WHERE clauses.
Re-cluster data when query performance starts degrading.
Use SYSTEM$CLUSTERING_INFORMATION function to check clustering quality.
d) Manage Storage Costs with Retention Policies
Storage in Snowflake is cheaper compared to compute, but over time unused data can still create unnecessary costs.
- Apply Time Travel retention wisely. Keep it short (1–2 days) unless compliance requires longer.
- Move historical data to cheaper storage tiers or use external stages (AWS S3, Azure Blob, Google Cloud Storage).
- Drop or archive unused tables and clones regularly.
e) Monitor Resource Usage with Resource Monitors
To avoid unexpected cost spikes, Snowflake provides resource monitors that track credit usage.
- Set daily or monthly credit quotas for each warehouse.
- Configure alerts when a threshold is crossed.
- Automatically suspend warehouses if limits are exceeded.
This gives full control and visibility over how credits are consumed.
f) Optimize Query Performance
Well-written queries are just as important as infrastructure tuning.
- Select only the columns you need (avoid SELECT *).
- Use result caching to speed up repeat queries.
- Break complex SQL into smaller steps using CTEs (Common Table Expressions).
Use materialized views for queries that run frequently with similar filters.
g) Scale Warehouses Dynamically
Not all workloads are equal. Some need high compute power for short bursts, while others require steady performance.
- For heavy transformations, scale up temporarily and scale down after the task completes.
- Use multi-cluster mode for high concurrency workloads where many users query simultaneously.
- Avoid keeping warehouses at high capacity during off-peak hours
h) Use Data Sharing Instead of Copying
Instead of copying data into multiple databases for different teams, Snowflake allows secure data sharing.
- Share datasets directly across accounts.
- Reduce duplication and storage costs.
- Keep one single source of truth for analytics.
i) Leverage Automation with Tasks and Streams
Automation reduces manual effort and prevents unnecessary compute usage.
- Use Tasks to schedule SQL jobs efficiently.
- Use Streams for incremental loads instead of full table reloads.
- Automate cleanup processes for staging and temporary tables.
j) Continuously Monitor and Optimize
Finally, performance tuning is not a one-time job.
- Review Query History and performance reports regularly.
- Track warehouse usage patterns to identify waste.
- Adjust warehouse sizes, clustering, and retention policies based on evolving workloads.
Conclusion
A Snowflake data pipeline is more than just loading tables; it is the full journey of data from ingestion through Snowpipe or batch loading, to staging in internal or external storage, followed by transformations with SQL or DBT, and finally automation using Streams, Tasks, or orchestration tools.
By mastering this flow in 2025, you gain the ability to:
- Build scalable, cost-friendly pipelines that keep data accurate and analytics-ready.
- Support real-time insights and machine learning use cases with clean, reliable data.
- Improve efficiency by reducing manual effort and speeding up decision-making.
For beginners, the best approach is to start small with one pipeline, then expand into transformations and automation as you grow.
Over time, these skills turn into a strong competitive edge because businesses need people who can design and manage cloud-native pipelines in Snowflake.
FAQ's
A Snowflake data pipeline refers to a system that facilitates the movement and transformation of data to the Snowflake cloud data platform.
This system enables organizations to source data, extract it from different locations, upload it into Snowflake, and subsequently transform it into a clean and usable format suitable for advanced reporting, analytics, and even machine learning.
Yes, Snowflake provides features like Snowpipe for continuous data ingestion and tasks for scheduling transformations.
These features make it easier to build automated, real-time, or batch data pipelines directly inside Snowflake.
Snowflake operates as a data warehouse in the cloud and it’s not an ETL tool.
This means, it integrates with ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) workflows.
Snowflake can be integrated with ETL tools like Fivetran, Talend, and Informatica to create scalable data pipelines.
Yes. Snowflake supports ELT pipelines very efficiently because transformations can be done inside Snowflake using SQL. Traditional ETL pipelines can also load processed data into Snowflake, depending on your architecture.
No, they are not the same. A data pipeline is a broader term that refers to the entire process of moving data from one place to another.
ETL is one type of data pipeline focused on extracting, transforming, and loading data. Snowflake data pipelines may use ETL, ELT, or other methods.
Snowflake is designed as an OLAP (Online Analytical Processing) database. It is built for analytics and reporting, not transactional workloads (OLTP).
This makes it ideal for data pipelines that support business intelligence, dashboards, and advanced analytics.
Some of the most popular ETL/ELT tools for Snowflake include Fivetran, Stitch, Talend, Informatica, dbt, and Matillion.
The best choice depends on your data sources, budget, and technical needs, but all integrate seamlessly with Snowflake to build powerful data pipelines.
In Snowflake, data pipelines can be classified into two main types:
- Batch pipelines – where data is loaded and processed in scheduled intervals.
- Streaming/real-time pipelines – where tools like Snowpipe continuously load data as it arrives.
This flexibility allows businesses to handle both historical data loads and real-time analytics in Snowflake.
Yes. ETL (Extract, Transform, Load) is one type of data pipeline. However, Snowflake is optimized for ELT (Extract, Load, Transform) because it allows raw data to be loaded first and then transformed inside Snowflake using SQL. Both ETL and ELT are commonly used with Snowflake data pipelines depending on the use case.
A typical Snowflake data pipeline goes through these five stages:
- Data Extraction: Collecting data from sources such as databases, APIs, or files.
- Data Ingestion: Loading the extracted data into Snowflake (often using Snowpipe).
- Staging: Storing raw data in Snowflake tables for processing.
- Transformation: Cleaning, joining, and enriching data using SQL or external ETL tools.
- Loading/Consumption: Making the transformed data available for reporting, dashboards, or machine learning.
The basic five stages of pipeline in Snowflake includes: Ingest, Store, Transform, Load, and Analyze. This structured approach ensures data flows smoothly from source to final analytics, making it reliable and efficient.