

A Practical Guide to Modern Data Warehousing Using Cloud Tools

- vijay
- July 23, 2025
- 2:04 pm
Table of Contents
What is Modern Data Warehousing?
Modern data warehousing means keeping your data in the cloud instead of on physical machines. It’s faster, easier to manage, and much more flexible.
Tools like Snowflake, BigQuery, and Redshift help teams pull in data from different places, store it safely, and run reports quickly even if you’re working with millions of records.
From my own work, I’ve seen how much smoother things run when you’re not worrying about servers or downtime.
You can scale up when traffic grows, cut back when it’s quiet, and focus on actually using your data, not just managing it.
So, if you’re tired of delays, crashing systems, or messy data setups, modern data warehousing is a better way forward.
Benefits of Using Cloud for Data Warehousing
Modern data warehousing means keeping your data in the cloud instead of on physical machines. It’s faster, easier to manage, and much more flexible.
Tools like Snowflake, BigQuery, and Redshift help teams pull in data from different places, store it safely, and run reports quickly even if you’re working with millions of records.
From my own work, I’ve seen how much smoother things run when you’re not worrying about servers or downtime.
You can scale up when traffic grows, cut back when it’s quiet, and focus on actually using your data, not just managing it.
So, if you’re tired of delays, crashing systems, or messy data setups, modern data warehousing is a better way forward.
Here are some of the biggest benefits of using the cloud for your data warehouse:
1. Scale Without the Headaches
In traditional systems, if your data doubled, you’d need to buy new servers, upgrade hardware, or expand your data center which takes time and money.
With cloud data warehousing, you can scale up instantly. Platforms like Snowflake or BigQuery allow you to increase compute power with just a few clicks. And when you no longer need that power, you scale back down.
Example:
An e-commerce site sees a huge spike in traffic during a holiday sale. With a cloud data warehouse, it quickly adds extra resources to handle more data without downtime or IT support.
1. Scale Without the Headaches
In traditional systems, if your data doubled, you’d need to buy new servers, upgrade hardware, or expand your data center which takes time and money.
With cloud data warehousing, you can scale up instantly. Platforms like Snowflake or BigQuery allow you to increase compute power with just a few clicks. And when you no longer need that power, you scale back down.
Example:
An e-commerce site sees a huge spike in traffic during a holiday sale. With a cloud data warehouse, it quickly adds extra resources to handle more data without downtime or IT support.
2. Pay Only for What You Use
One of the biggest advantages of cloud is cost efficiency. You’re not locked into expensive licenses or paying for unused server space. Instead, you’re billed based on how much storage or compute you actually use.
Example:
A small startup uses Redshift only during working hours. They don’t pay for idle time at night or on weekends, keeping costs low.
This “on-demand” pricing works well for businesses of all sizes especially those with unpredictable workloads.
3. Access Data Anytime, Anywhere
Cloud-based platforms are web-accessible. As long as you have internet, you can log in and work with your data. This is a game changer for remote teams or companies with offices in different locations.
Example:
A marketing analyst working from home in Hyderabad can easily log in to the Snowflake dashboard and view campaign data without connecting to the office network.
No VPNs, no remote desktop — just open your browser and go.
4. Improve Performance
Modern cloud warehouses are built to handle large volumes of data and multiple users at once. Queries run faster, reports load quicker, and there’s no “system slowdown” like in old on-premise setups.
Example:
A financial services team used to wait 10–15 minutes for reports to load. After switching to BigQuery, the same reports load in seconds — even with larger datasets.
Better performance means better decisions, faster.
5. Easy Integration with Other Tools
Cloud data warehouses work well with ETL tools (like Fivetran, Airbyte), BI platforms (like Tableau, Looker, Power BI), and even machine learning systems. Most offer direct connectors and APIs.
Example:
A sales team connects their CRM (like Salesforce) to Snowflake using Fivetran. Data flows automatically, and dashboards update in real-time without manual uploads. This saves hours of effort every week.
6. Reduce Maintenance
With older systems, there was a need to monitor server performance, implement software updates, manage storage expansions, conduct backups, and address power concerns, typically requiring the employment of specialized IT personnel.
Example:
A retail company utilizing Redshift doesn’t require its own team to manage servers internally. Amazon takes care of updates, backup scheduling, and patching behind the scenes.
7. Strong Security Features
Cloud platforms offer enterprise-grade security: data encryption, role-based access, activity logging, and compliance with regulations like GDPR or HIPAA.
Example:
A healthcare provider uses Snowflake to store patient data. Data is encrypted both at rest and in transit. Only authorized users can access specific data fields, keeping sensitive info safe.
8. Faster Setup and Deployment
Traditional data warehouses can take months to set up from ordering hardware to installing software. With the cloud, you can get started in hours or days.
Example:
A startup launches a new product and wants to track user data from day one. Using BigQuery, they create a working data warehouse in a single afternoon no hardware, no waiting.
Why Move to the Cloud for Data Warehousing?
When you’re working with growing data, slow systems, or rising costs, moving your data warehouse to the cloud is no longer just a tech upgrade, it’s a smart business decision.
I’ve personally seen teams go from frustrated and overworked to confident and data-driven, just by switching to the cloud.
Here’s why making that move makes a real difference:
Elasticity and auto-scaling
In traditional systems, if your company suddenly needed more power like during peak sales or reporting season you had to request new servers, wait for approvals, and maybe even pause your work.
In the cloud, you don’t have to plan ahead for growth. Most platforms (like Snowflake or BigQuery) scale automatically based on your workload.
If your team runs heavy queries, the system adds more compute power instantly. When the demand drops, it scales back — all on its own.
Real world Example
During a product launch, one retail company I worked with saw traffic triple in a day. Thanks to auto-scaling in their cloud warehouse, there were no delays, no crashes everything just worked.
Pay-as-you-go pricing
With traditional data warehousing, you often pay upfront for storage, servers, licenses whether you use them or not. That’s not ideal, especially for growing or seasonal businesses.
Cloud systems solve this. You only pay for what you actually use. If your queries are light this month, your bill is lower. If you scale up during a busy period, you pay for that time only and then go back to normal.
Why it matters
You stay in control of your budget. There’s no waste, no surprise maintenance costs, and no guessing. This kind of pricing works well for startups, enterprises, and everything in between.
No hardware maintenance
I remember working with systems where a single hardware failure could delay everything sometimes for days. You had to deal with servers, storage upgrades, power backups, and physical space. It was tiring and expensive.
Cloud platforms remove that problem completely. You don’t need to manage any hardware, because the service provider takes care of all of it including updates, backups, and security patches.
Why it’s better
Your team focuses on data and results not fixing things or waiting on IT support. It saves time and reduces stress.
Global accessibility and collaboration
One of the biggest benefits I’ve seen is how easily teams can work together from different locations. With a cloud data warehouse, anyone with permission can access the same data from anywhere — office, home, or even while traveling.
Real-world example
At one company I supported, the marketing team was in India, the product team in the U.S., and the CEO in Dubai. Thanks to Snowflake, all of them were able to view up-to-date reports on the same dashboard no delays, no version conflicts.
Cloud makes teamwork smoother, faster, and more connected. You no longer need to send files back and forth or wait for someone to “upload the latest version.” It’s all live, all the time.
On-premise warehouse vs Cloud data warehouse
Feature | On-Premise Data Warehouse | Cloud Data Warehouse |
Setup Time | Weeks to months | Hours to days |
Cost Model | High upfront cost (hardware, licenses) | Pay-as-you-go (only for what you use) |
Scalability | Manual and limited | Instant and flexible |
Maintenance | Handled by in-house IT team | Handled by the cloud provider |
Accessibility | Access limited to physical or VPN-connected users | Accessible from anywhere via internet |
Performance | Slower with large data volumes | Faster with built-in auto-scaling |
Security & Compliance | Fully controlled in-house | Managed by provider with built-in standards |
Integration | May require custom setups | Easy integration with modern tools |
Disaster Recovery | Manual backups and recovery plans | Automated backup and recovery |
With on-premise systems, everything takes longer from setup to upgrades. You need to buy servers, manage storage, and always rely on your IT team when something goes wrong. It gives you full control, but it also brings more responsibility and cost.
On the other hand, cloud data warehousing feels like freedom. You spin it up in a few clicks, scale when your data grows, and pay only for what you use. Plus, no late-night calls to fix a crashed server, the provider handles it all in the background.
Top Cloud Tools for Data Warehousing
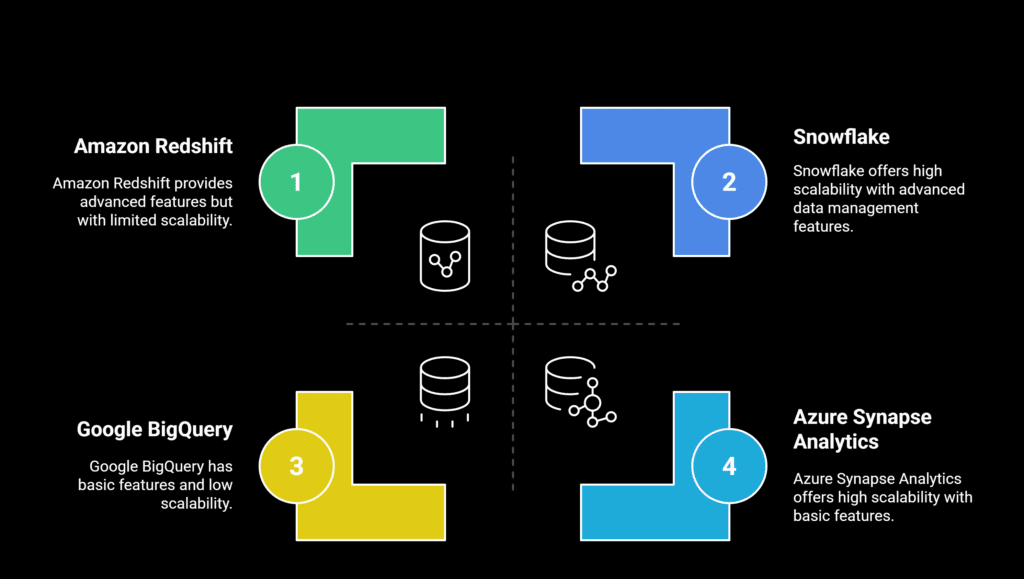
Below is an analysis of the top cloud data warehousing tools that are and extensively utilized, features and strengths.
1. Snowflake
Snowflake is one of the most popular cloud data warehouse platforms today. What makes it stand out is how simple and flexible it is.
It separates storage and compute, meaning you can scale them independently a big advantage when your data grows unevenly.
Why teams like it
- It works across multiple clouds (AWS, Azure, GCP)
- You can run many workloads at the same time without affecting speed
- It’s great for structured and semi-structured data (like JSON)
Real Example
I worked with a retail company that used Snowflake to track both online and in store customer data. They could run real-time reports while ETL jobs were still loading no slowdowns.
2. Amazon Redshift
Redshift is Amazon’s cloud data warehousing solution. If you’re already using AWS for other services, Redshift fits right in. It’s fast, reliable, and supports huge datasets.
Why it’s useful
- Strong performance for large, complex queries
- Integrates well with other AWS services (like S3, Glue, and QuickSight)
- Offers Redshift Spectrum to query data directly in S3
Real Example
A logistics company I worked with used Redshift to manage delivery data from thousands of locations. Its ability to handle large joins and filters saved hours of processing time every day.
3. Google BigQuery
BigQuery is a fully serverless data warehouse from Google Cloud. You don’t need to manage any infrastructure, and you can analyze terabytes of data using standard SQL. It’s known for its speed and ease of use.
why people choose it
No need to manage servers , just load data and run queries
4. Azure Synapse Analytics
Formerly known as Azure SQL Data Warehouse, Synapse brings data warehousing and big data together. It’s part of the Microsoft ecosystem and works well with other Azure services.
What it offers
- Combines data warehousing with big data analytics in one platform
- Connects easily to Power BI and other Microsoft tools
- Useful for teams already using Azure-based systems
Real Example
A healthcare analytics firm I collaborated with used Synapse for advanced reporting. Since they were already using Microsoft tools, integration was smooth and efficient.
5. Databricks (Lakehouse Platform)
Databricks is slightly different , it combines a data warehouse with a data lake, often referred to as a Lakehouse. It’s great for teams working with both traditional data and big data or machine learning workloads.
Key benefits
- Strong support for both SQL and data science workflows
- Great for real-time streaming data and large datasets
- Offers built-in machine learning capabilities
Real Example
A media company used Databricks to analyze user engagement across video platforms. They combined structured ad data with raw viewing logs to build predictive models — all in one place.
- Excellent for large-scale analytics and machine learning use cases
- Billed based on query size and storage used
Want to learn Snowflake? If yes Click here
or want to continue reading about Modern Data Warehousing in snowflake
Step-by-Step Implementation Guide for Modern Data Warehousing
The following steps will guide you through the process and set you up for success.
1. Define Your Business Goals:
Prior to diving into tools or platforms, make sure to understand the reasons behind your need for a data warehouse. Are you trying to track customer behavior? Improve reporting speed? Centralize scattered data?
Example
An online store wants to analyze customer purchases and website behavior in one place to personalize marketing.
Knowing the “why” helps guide every other decision from choosing tools to designing data models.
2. Choose the Right Cloud Platform :
The most popular ones are:
- Snowflake (great for scaling and multi-cloud)
- Google BigQuery (best for analytics and speed)
- Amazon Redshift (tight AWS integration)
- Azure Synapse (strong for Microsoft-based environments)
Example
- If your team uses a lot of Google tools go with BigQuery.
- If you’re already in AWS Redshift might be easier to integrate.
- Start with a small proof of concept before committing long-term.
3. Design Your Data Architecture :
Now plan how your data will flow:
- Where is the data coming from? (CRM, sales apps, websites?)
- How should it be organized? (Star schema? Snowflake schema?)
- How often will it update? (Daily? Real-time?)
Example
- A logistics company decides to build a star schema with central “Orders” and surrounding dimensions like “Customer,” “Product,” and “Location.”
- Good architecture ensures fast queries and easier reporting later.
4. Set Up Data Ingestion (ETL/ELT) :
Use ETL (Extract, Transform, Load) or ELT (Extract, Load, Transform) tools to bring your data into the warehouse.
Popular tools are :
- Fivetran
- Airbyte
- Apache NiFi
- DBT (for transformations)
Example
A startup connects their PostgreSQL database and Shopify store to Snowflake using Fivetran. It pulls new data every hour without manual effort. Automating ingestion saves hours of time and reduces errors.
5. Clean and Transform Your Data
Use transformation logic to clean, shape, and organize it.
- Rename columns for clarity
- Remove duplicates
- Standardize formats (e.g., dates, currencies)
- Create business logic (e.g., “active customers” or “monthly revenue”)
Tool Tip: Use dbt (Data Build Tool) — it lets analysts write transformations in SQL and schedule them easily.
Example
A marketing team transforms raw campaign data into a cleaned “Campaign Performance” table used by dashboards.
6. Set Up Access and Permissions
Decide who can view or edit data in the warehouse. Set up roles for different teams like Marketing, Finance, or Data Science and apply access control.
Example
Finance team gets access to revenue and budget data, but Marketing can only view customer engagement metrics. This kepps your data more secure and organized.
7. Connect BI Tools for Reporting :
Now that your data is in place, connect a dashboard or reporting tool:
- Power BI
- Tableau
- Looker
- Google Data Studio
Example
A sales team connects Looker to BigQuery and sets up a live dashboard showing daily conversions, top products, and regional performance. Visualizing data helps everyone make faster, smarter decisions.
8. Monitor, Optimize, and Maintain :
Once live, check performance regularly:
- Are queries running fast?
- Is data loading on schedule?
- Are costs within budget?
- Are users getting the reports they need?
Most cloud platforms have built-in monitoring tools to track usage and performance. Use these to improve over time.
Example
An operations team notices a report slowing down. They identify a missing index and fix it within minutes using Snowflake’s Query Profiler.
9. Document Everything
As you build your warehouse, keep clear documentation:
- Data source details
- Transformation rules
- Table definitions
- Access roles
This helps new team members onboard faster and reduces confusion. Tip: Use tools like Confluence or Notion for internal documentation.
Architecture of a Cloud-Based Data Warehouse
The term “cloud data warehouse” may seem complex initially, but essentially, it provides an efficient method for managing the flow, storage, processing utilization of data for making business decisions.
I have experience with various cloud-based platforms such as Snowflake and BigQuery, and although they vary in certain aspects, they generally share a common structure.
Here is a basic overview of the five essential layers and how they interact.
1. Data Ingestion Layer (Batch and Streaming)
Every business collects data differently. Some send it in chunks (batch), while others send it continuously (streaming). Both methods are common and useful, depending on the type of data and how quickly it needs to be processed.
- Batch ingestion is scheduled. For example, uploading a sales report at the end of each day.
- Streaming ingestion happens in real time like tracking user clicks on a website as they happen.
Example
An online clothing store might batch upload their daily orders each night, but real-time data like website visits or product views during the day to spot trends quickly.
This layer helps organize all incoming data and ensures nothing is missed, whether it comes in once an hour or every second.
2. Storage Layer
When data arrives at the warehouse, it requires storage that’s the purpose of this layer.
In contrast to conventional systems, cloud warehouses differentiate storage from processing, allowing your data to remain secure without consuming computational resources until required.
The majority of cloud platforms are capable of managing both structured data (such as tables) and semi-structured data (like JSON files). Your data is automatically sorted, compressed, and stored effectively — without requiring you to arrange folders or databases by hand.
In Snowflake, you can upload sizable files (such as customer information or product details) without concerns about file format or disk space. It simply functions.
This level focuses on securely storing your data and ensuring it’s easily accessible whenever you require it.
3. Compute / Processing Layer (ETL, ELT)
This is where the raw data turns into something useful.
After storage, you usually need to clean, reshape, or combine your data before analyzing it. That’s done through ETL or ELT processes:
- ETL (Extract, Transform, Load): Clean and format your data before storing it.
- ELT (Extract, Load, Transform): Load raw data first, then process it inside the warehouse.
Most modern warehouses prefer ELT because the cloud can handle large transformations easily.
Example
Let’s say you import customer feedback from multiple platforms. You load everything into BigQuery first, then use SQL queries to clean up duplicate entries and group responses by region.
This layer makes sure your data is accurate and analysis-ready.
4. Analytics & BI Tools Integration
This is the layer most people interact with daily — dashboards, reports, and visual insights.
Once your data is cleaned and ready, you can connect it to tools like Tableau, Power BI, Looker, or even Google Sheets. These tools pull the latest data directly from your warehouse and help you understand what’s happening in your business.
Example
A manager opens a Power BI dashboard linked to Redshift and sees live sales numbers across all stores. No need to email Excel files or wait for IT — the report is always up to date.
This layer turns raw data into clear decisions.
5. Governance & Security Layer
Lastly, there’s the layer that keeps everything under control.
This is where you decide who can access what, how data is protected, and what rules apply to sensitive information. It’s crucial for staying secure and compliant with data regulations.
Good cloud platforms include features like:
- User roles and permissions
- Encryption of data
- Activity monitoring
Access control and audit logs
Example
A finance team in a company uses Snowflake to view budget data, but the HR team can’t see it and vice versa. Everything is managed through user roles, and changes are tracked automatically.
This layer builds trust in your data and ensures it’s handled responsibly.
Want to learn Snowflake? If yes Click here
or want to continue reading about Modern Data Warehousing in snowflake
How to Set Up a Cloud Data Warehouse: Step-by-Step Guide
Setting up a cloud data warehouse might sound complex, but when done step-by-step, it becomes manageable. I’ve been part of multiple data projects, and I can tell you it’s more about smart planning than heavy coding.
Here’s a simplified and practical way to approach it:
Choose a cloud platform/tool:
The initial task is to identify a cloud data warehouse option that aligns with your organizational requirements.
Among the leading alternatives are:
- Snowflake
- Google BigQuery
- Amazon Redshift
- Microsoft Azure Synapse Analytics
When choosing a platform, consider a few key things: your budget, the volume of data, how quickly you need results, and whether your team prefers SQL or other tools.
2. Design the Right Data Model
Once you’ve selected a platform, the next step is to design your data model. This is like the blueprint of your data warehouse. It defines how your data is organized and connected.
Two common models are:
- Star schema: Simple and fast for reporting. It has one central fact table (like sales data) connected to smaller dimension tables (like products or regions).
- Snowflake schema: More detailed and normalized. It’s good for reducing duplication but slightly more complex to manage.
Why this matters:
A clear data model makes your reports faster, your data easier to maintain, and your queries more accurate.
3. Set Up Data Ingestion
Data ingestion is how you bring data into your warehouse. This can come from CRMs, ERPs, marketing tools, or custom databases.
There are three main ways to set up ingestion:
- Managed tools like Fivetran – Easy to use, low-code connectors for tools like Salesforce, Shopify, or Google Ads.
- Open-source tools like Airbyte – Good for custom setups and cost savings.
- Custom ETL scripts – Useful if you need full control or are connecting legacy systems.
Real Tip :
If you’re just starting, tools like Fivetran can save a lot of time. You can always move to custom pipelines later when you need more control.
4. Configure Compute and Storage
Cloud data warehouses separate compute (processing) from storage (data at rest). This setup allows you to scale each one independently based on usage.
Here’s what you need to do:
- Set up compute clusters – These handle data processing tasks. You can scale them up during heavy reporting times and scale down when idle.
- Configure storage settings – Choose how and where data is stored. Cloud platforms usually handle compression, backup, and redundancy automatically.
Best Practice :
Snowflake allows you to create virtual warehouses that can be paused when idle to control costs, whereas BigQuery’s pricing model is based on query execution and data storage, making it essential to carefully plan and manage your usage to avoid unnecessary expenses.
5. Connect Your BI Tools
After your data has been collected, refined, and organized, the next step is to transform it into actionable insights using Business Intelligence (BI) solutions.
These tools empower non-technical stakeholders to derive meaningful conclusions from the data, eliminating the need for technical expertise in SQL.
Popular BI tools include:
- Power BI
- Tableau
- Looker
These tools can be connected directly to your data warehouse using built-in connectors or APIs.
Real example:
You can connect Tableau to Snowflake and create a sales dashboard showing weekly trends by region. The report stays up-to-date because it pulls data directly from the cloud.
Pro tip :
Make sure only the necessary data is exposed to avoid slow reports or unnecessary access to sensitive information.
6. Apply Monitoring and Data Governance
After everything is set up, it’s important to monitor your data and apply proper governance. This ensures your data is accurate, secure, and compliant with business and legal rules.
Tools that help with this include:
- Monte Carlo – Helps detect data quality issues early like missing values or broken pipelines.
- Collibra – Supports data cataloging, governance policies, and access management.
Why this is important:
Even the best setup can fail if no one is watching. Alerts for failed ingestions, unusual spikes, or access by unauthorized users can save your business from costly mistakes.
Simple step to begin:
Start with clear roles define who can view, edit, and manage your data. Set up basic alerting for failed data loads or slow-running queries.
Key Challenges in Cloud Data Warehousing
The emergence of cloud data warehousing has revolutionized how organizations store and process data.
It provides increased scalability and cloud capabilities, improved processing speed, and enhanced flexibility. Nevertheless, organizations encounter several problems, even with clear benefits.
If you fall into any of the following categories: analytics manager, data engineer, or novice, addressing the major concerns of cloud data warehousing will be highly beneficial.
It is conducive to analyze each of the issues stem one by one.
1. Cost Overruns in Cloud Data Warehousing
One of the biggest surprises for many teams is how quickly cloud costs can go up.
Most cloud data warehouses use a pay-as-you-go model. That sounds good at first you only pay for what you use.
But without proper planning or control, usage can increase quickly, and your bills can grow without warning.
What causes cost overruns:
- Running large queries without optimization
- Loading and storing duplicate or unused data
- Keeping virtual warehouses running even when idle
Allowing too many users to run heavy operations at once
Real example:
A team runs a dashboard that refreshes every hour, but the underlying query is not optimized. It scans billions of rows daily leading to high compute charges. No one notices until the monthly bill arrives.
How to fix it:
- Set query limits and schedules for non-critical dashboards
- Monitor warehouse usage and scale down when not in use
- Clean up unused tables or historical data
- Use auto-suspend and auto-resume features in platforms like Snowflake
By tracking and optimizing your workloads, you can reduce cloud spend without sacrificing performance.
2. Data Quality and Observability
Cloud warehouses store large volumes of data from multiple sources. If the data going in is messy, outdated, or missing fields, then even the best dashboards will give you wrong results.
What is data observability:
It means having clear visibility into how your data flows, where it’s breaking, and how fresh or accurate it is.
Common data quality issues:
- Duplicate entries
- Mismatched values (like 01/01/2025 vs 1st Jan 2025)
- Missing or null values in important columns
Delays in data pipelines causing stale data
Real example:
A retail company updates product prices daily. But due to an issue in the pipeline, the latest prices didn’t load for two days — leading to incorrect sales margins being shown on reports.
How to fix it:
- Implement data validation checks before loading
- Use tools like dbt, Monte Carlo, or Great Expectations for testing
- Monitor freshness, completeness, and consistency regularly
- Build alert systems for pipeline failures or delays
Clean, reliable data helps decision-makers trust the reports they use.
3. Skill Gaps in SQL and Cloud Tools
Many organizations move to cloud platforms like Snowflake, BigQuery, or Redshift but struggle to use them fully because their teams lack the right skills.
Common Sklill Gaps :
- Writing efficient SQL queries
- Understanding how cloud warehouses scale and store data
- Automating pipelines and managing orchestration tools
Managing cloud billing and performance tuning
Real example:
An analyst writes a basic SQL query that works, but it takes 10 minutes to run. A senior engineer rewrites it using common table expressions and filters and it runs in 10 seconds.
How to address this:
- Offer regular training for your team on cloud platforms
- Encourage use of documentation and online communities
- Build knowledge-sharing sessions within your company
- Start with easy tools like dbt for transformations instead of complex scripts
Investing in skill-building helps teams work smarter and reduces costly mistakes in production.
4. Compliance and Data Governance
The start of cloud data warehousing has revolutionized how organizations store and process data. It provides increased scalability and cloud capabilities, improved processing speed, and enhanced flexibility. Nevertheless, organizations encounter several problems, even with clear benefits.
If you fall into any of the following categories: analytics manager, data engineer, or novice, addressing the major concerns of cloud data warehousing will be highly beneficial.
Common challenges:
- Not knowing who accessed what data
- Missing encryption or data masking for sensitive fields
- Data being shared outside approved regions
No clear data retention or deletion policies
Real example:
A company accidentally stored customer ID numbers in a shared reporting table. Without access restrictions, multiple teams could view that sensitive data, creating a privacy risk.
What to do:
- Set user roles with strict access permissions
- Mask sensitive data fields using built-in functions
- Track access logs and usage with audit features
- Keep data in regions allowed by local laws and your compliance needs
Using proper data governance tools and best practices makes your warehouse not only more secure but also more trustworthy.
Data Warehouse vs Data Lake Real Difference?
As a beginner in the field of data analysis or if you have been working in cloud environments, it is likely that you have come across the terms data warehouses and data lakes.
Though the terms sound alike, these two services have different functions.
Understanding what is data warehouse and data lake is, can greatly assist your team in making the right choices when it comes to storing, processing and analyzing the data, particularly when working with big data.
we will have a look at some key differences in the simplest way.
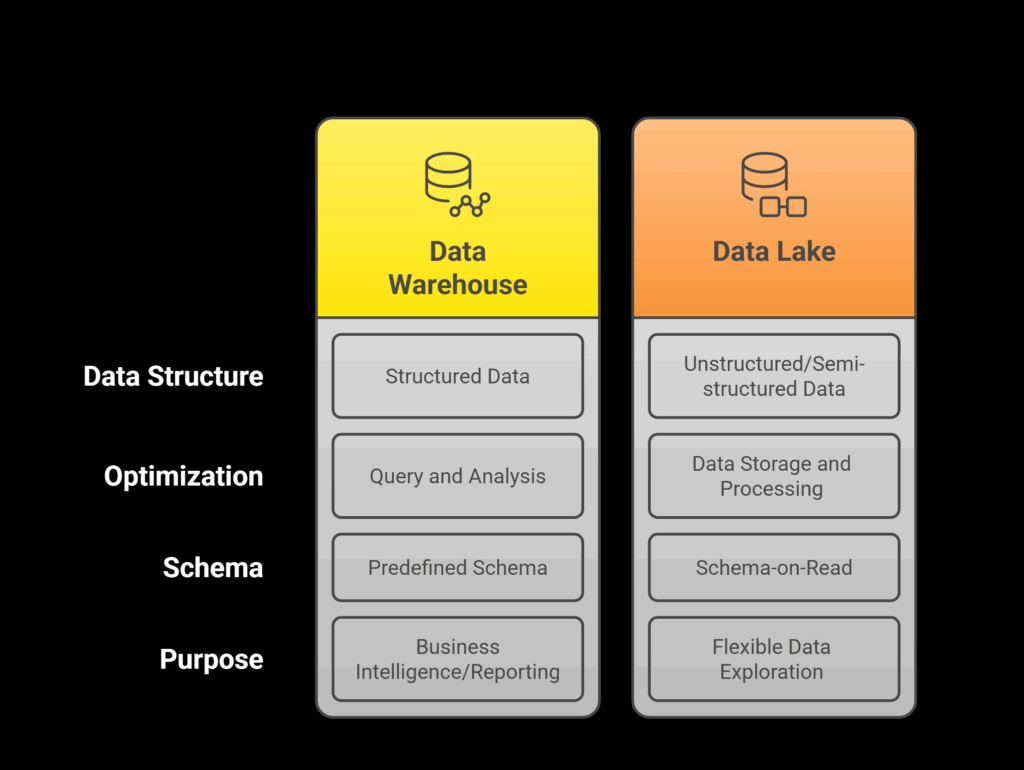
Data Warehouse :
A data warehouse is an organized framework that stores processed and well-structured data, primarily intended for business analysis and reporting purposes.
We can compare data warehouses to organized libraries, where every ‘book’ or data set is put in its correct ‘section’ and labeled, enabling easy access.
The data is best when known, well-defined, and used often for business evaluations or financial analysis.
Tools used for data ware house:
Snowflake, Amazon Redshift, Google BigQuery, Microsoft Azure Synapse
Data Lake
A data lake is a storage architecture that gathers datasets in diverse forms such as structured, semi-structured, and unstructured data including logs, videos, and sensor data.
Tools used for data lake:
Amazon S3, Azure Data Lake Storage, Google Cloud Storage, Hadoop HDFS
Comparison table for Data Warehouse vs Data Lake:
| Point of Comparison | Data Warehouse | Data Lake |
|---|
| Main Use | Stores well-organized data to help with regular reports and business tracking. | Keeps all kinds of data in one place, even if it’s not cleaned or sorted yet. |
| Data Types | Works best with neat, structured data like spreadsheets and database tables. | Accepts all formats – from Excel sheets to videos, images, logs, and raw files. |
| How It Stores Data | Structures the data before saving it, so it’s ready to use right away. | Saves data as it comes in, and organizes it later when someone needs it. |
| Who Usually Uses It | Business teams, analysts, and data professionals use it to check trends and make decisions. | Developers, researchers, and data scientists use it for experiments and large projects. |
| Popular Tools | Examples include Snowflake, BigQuery, Redshift, and Azure Synapse. | Common ones are Amazon S3, Hadoop, Azure Data Lake, and Google Cloud Storage. |
| How Data Is Handled | Uses ETL (data is cleaned first, then loaded). | Often uses ELT or just loads raw data first, then processes it when needed. |
| Speed for Queries | Fast for regular reports and dashboards using structured data. | Slower for complex queries unless tuned with the right tools. |
| Cost Factor | Can be costly as it uses high-performance systems. | More affordable for large volumes of mixed data. |
| Flexibility | Not very flexible — expects data to be tidy and consistent. | Very flexible — lets you store any kind of data without rules. |
| Scalability | Scales well but cost increases quickly with more data. | Easy to scale up for massive data without high cost. |
| Security & Access | Strong built-in controls for data privacy and user roles. | Needs extra tools to manage safety, especially for sensitive data. |
| Best Fit For | Sales reports, business dashboards, and finance tracking. | Storing logs, real-time data, and content for machine learning or future use. |
| Compliance Ready | Easier to meet data rules like GDPR due to its clean format. | Needs more setup to meet data laws depending on how it’s managed. |
| Data Handling Over Time | Works with ready-to-use, updated data. | Keeps old, new, and raw data – supports full data history. |
Use Cases for Hybrid Data Warehouse and Data Lake Solutions
Sometimes, businesses need both. That’s where a hybrid architecture makes sense. Here are some common use cases where combining a data warehouse and data lake can be helpful:
1. Advanced Analytics and Machine Learning
Machine learning models often need large, raw datasets like user logs or sensor data. These live in the data lake.
But after the model is trained and results are generated, the output (like prediction scores) is sent to the data warehouse for business use.
Example
A bank uses raw transaction data in the data lake to detect fraud using ML. The final fraud alerts are then stored in the data warehouse for reporting.
2. Unified Customer View
Customer data can come from many sources CRM, support tickets, feedback, and web behavior.
A data lake can store all of it, even in messy formats. A cleaned-up version can be sent to the data warehouse to create a 360-degree customer profile.
Example
An eCommerce business uses the lake to store clickstream data and the warehouse to run loyalty programs or personalized offers.
3. Real-Time and Historical Analysis
Data lakes are great for storing real-time and raw logs. Warehouses are better for historical summaries and reporting.
Example
A logistics company tracks truck GPS in the lake in real time but uses the warehouse to analyze monthly delivery times.
4. Cost Optimization
Storing all data in a warehouse can be expensive. Instead, raw and infrequently used data is stored in the data lake. Only important, cleaned data is moved to the warehouse, saving money.
Example
A media company stores all video usage data in the lake but only moves summary stats like watch time to the warehouse.
5. Data Discovery and Innovation
Sometimes, analysts need to explore data freely to find patterns or test ideas. A data lake allows this kind of discovery. Once insights are found, useful data is moved to the warehouse for long-term use.
Example
A startup explores user interaction data in the lake to find trends, and later uses that cleaned data in the warehouse for regular product updates.
Conclusion
We have discussed how modern cloud data warehouses function, their basic structure, and their key advantages for business operations.
The cloud improves every step of the process, from data ingestion to storage and processing, and even to integration with business intelligence tools.
All of these steps become cheaper and more scalable. As a data engineer, a business analyst or a decision maker, knowing the ins and outs of a cloud-based data warehouse which will undoubtedly help you devise intelligent systems, optimize decisions, and prepare for the data driven future.
FAQ's
A few of the most common services used for data warehousing assist with the storage, processing, and analysis of colossal amounts of data.
They are:
- Snowflake for data storage and compute.
- Amazon Redshift for scalable data warehousing on AWS.
- Google BigQuery for rapid and efficient analytics and queries in the cloud.
- ETL tools such as Apache NiFi, Talend, and Informatica for data movement.
- BI tools such as Power BI
- Tableau, and Looker for data visualization
All tools help in collecting data, preparing the data, and cleaning it for effortless access during the decision making process.
Modern data warehousing, as the name suggests, is the progression of managing & analysis of data using the cloud.
It helps customers:
- Store structured data as well as semi-structured data.
- Empower businesses to scale resources as needed without the need to physically upgrade hardware.
- Access semi-structured data as well as structured data in real time & in batches from one central location.
- Easily connect to interfaces for machine learning, business intelligence, or other related systems.
- This creates faster access to data, gives flexibility in the application’s usefulness, and ultimately is cheaper to store.
A cloud data warehouse is a business with a specific platform that helps to store data and processes it over the internet.
It assists teams to:
- Work with spatial data, and access data from anywhere at any time.
- Greatly reduce costs associated with infrastructure and maintenance.
- Scale both storage and compute to on demand.
- Protect in cloud level security for data using built in cloud level security.
Some other examples of cloud data warehouses include Snowflake, BigQuery, and Redshift.
ETL tools are used to Extract, Transform, and Load data into a warehouse.
They help in:
- Accessing data from various sources; be it files, APIs, or databases.
- The organization, cleansing, as well as enrichment of data.
Loading the data into the warehouse to enable analysis.Some of the favored ETL tools are Talend, Informatica, Fivetran and AirFlow. These tools enhance data quality and reduce manual effort.
Currently, the ETL tools gaining the most popularity and use are Fivetran, Airbyte, and Hevo Data.
These tools:
- Lower the amount of coding required to automate data pipelines.
- Update data in real-time or nearly real-time.
- Integrate easily with cloud warehouses like Snowflake or BigQuery.
They are very beneficial to startups and modern teams who require speedy and easy data integration.
Some suggested tools would be:
- AWS Glue for serverless ETL jobs.
- Amazon Data Pipeline for scheduled data workflows.
- Apache Airflow on AWS MWAA for advanced pipeline orchestration.
Steps:
- Extract data from S3, RDS, or from on-premise systems.
- Use PySpark or AWS Glue scripts to transform it.
- Put the data into Amazon Redshift or S3 for final computation.
Finally, analyze the data.Talend and Informatica are other partner tools AWS supports.
Planning a modern data warehouse requires thinking about flexibility, speed, and size.
The key steps include:
- Understanding business needs. Who will be accessing and utilizing the data?
- Choosing a cloud platform. Leading options include Snowflake, BigQuery, and Redshift.
- Set up raw and processed data staging layers.
- Integrate Fivetran, dbt, or Airbyte as ETL or ELT tools.
- Implement data governance and access restriction policies.
A data warehouse is best when it is designed to support real-time and batch data as well as scale over time alongside your data requirements.
These are the three key categories of data warehouses:
Enterprise Data Warehouse (EDW): These serve as the primary repository for an organization’s accumulated data and is best for historical analysis.
Operational Data Store (ODS): These serve operational data, mainly for short-term business functions. These provide up-to-date or close-to real-time data.
Data Mart: These are targeted data warehouses for individual business units like sales and marketing and are smaller in size and scope.
These categories are designed to address specific needs in an organization.
Snowflake is a well known cloud data warehouse that offers the following capabilities:
- The ability to support structured and semi-structured data.
- Independent scaling of compute and storage.
- Run different workloads concurrently without causing a performance dip.
- Perform data querying and transformation using SQL.
- Integrate with Power BI, Tableau, and dbt.
Even with larger data sets, Snowflake maintains its reputation for its user friendliness, data security, and quick performance.
No, Databricks is not a data warehouse. It is a data lakehouse platform, which means it incorporates aspects of both a data lake and data warehouse.
- It offers capabilities in big data processing, artificial intelligence, and machine learning.
- It has scalable data operations using Apache Spark.
- Raw, structured, and unstructured data can all be stored in a single repository.
While Snowflake is more appropriate for BI reporting, Databricks is ideal for advanced analytics and data science work.
Below is a list of essential tools needed for managing a data warehouse.
Cloud Platforms: Snowflake, Redshift, BigQuery.
ETL/ELT Tools: Talend, dbt, Fivetran, Airflow.
BI Tools: Power BI, Looker, Tableau.
Data Quality and Monitoring: Monte Carlo, Great Expectations.
Security and Governance: Collibra, Alation, or cloud native IAM tools.
The tools listed are effective in collecting, cleaning, storing, analyzing, and securing data.
Data warehouse tools enable us to:
Combine various different multi-sourced data collections centralized to one database to streamline processes for all users.
Enhance decision-making strategies with real-time and authentic data.
Preprocess data cleansing and transforming for reshaping analyzed data.
Use charts and dashboards for enhanced visual data representation.
Manage restricted and guarded governance for data protection.
Data warehouse and central management tools eliminate manual processes and streamline workflows for users enabling to save time and effort when handling bulk data.
A data warehouse stores structured data that is ready for analysis. It’s like a well-organized digital library where everything is cleaned, formatted, and easy to search.
A data lake stores raw data in its original format structured, semi-structured, and unstructured. Think of it like a big water tank filled with all kinds of data that you can clean and use later.
Example:
- In Snowflake, data warehouse stores tables ready for business reports.
Data lake stores raw logs, JSON, CSV files, and sensor data before processing.
In ETL (Extract, Transform, Load), a data lake is often the landing zone for raw data. Data from different sources is first dumped into the data lake. Later, it’s processed and moved into a data warehouse for analytics.
Snowflake Use Case:
Raw IoT sensor data can be loaded into Snowflake external stages (like S3 or Azure Blob) acting as a data lake before transforming it.
A data space refers to a shared environment where data assets are organized by domains or business functions, often across teams or departments.
A data lake is a central storage that holds all kinds of raw data without strict structure.
In Simple Words:
- Data space is about sharing and organizing data.
- Data lake is about storing all types of data for future use.
A data warehouse is a place to store and analyze data.
A dataflow is a process that moves and transforms data from one system to another.
Snowflake Example:
Dataflow tools like DBT, Apache Airflow, or Azure Data Factory can load and clean data before saving it into a Snowflake data warehouse.
- Data Lake: Stores raw and unprocessed data from many sources.
- Data Warehouse: Stores clean, structured data for business analysis.
- Data Mart: A small part of a data warehouse focused on a specific team or function (like sales or marketing).
Snowflake Insight:
You can create separate virtual data marts using virtual warehouses in Snowflake, all sourcing from the same central data lake or warehouse.
Data Warehouse
- Optimized for analytics
- Structured data only
- High performance for reporting
Data Lake
- Flexible storage
- Handles all data types
Used for machine learning and big data processing
- EDW (Enterprise Data Warehouse): A large, central system where business-ready data is stored for the entire company.
- Data Lake: A flexible storage system that keeps all raw data until it’s needed.
With Snowflake:
You can build both EDW and data lake on a single platform using features like separate compute for each workload, and stages for raw data.
ETL stands for:
- Extract: Pull data from sources
- Transform: Clean, format, and enrich the data
- Load: Put the final data into the data warehouse
Snowflake Usage:
Snowflake supports both ETL and ELT. Tools like Fivetran, DBT, or Talend extract data, then either transform before loading or transform inside Snowflake after loading.
Some common data warehouse platforms:
- Snowflake
- Amazon Redshift
- Google BigQuery
- Microsoft Azure Synapse Analytics
- Teradata
A virtual warehouse in Snowflake is a compute resource. It runs queries, loads data, and processes transformations. It can be paused when not in use to save cost.
Yes. Snowflake supports unstructured data using stages, meaning it works as both a data lake and a data warehouse in one system.